AI IN HET INFORMATIEDOMEIN (6) SIMON BEEN
Wat is de impact van kunstmatige intelligentie op het informatiedomein? In een reeks artikelen wordt ingegaan op persoonlijke activiteiten binnen het informatiedomein en veranderingen in organisatieprocessen en de informatieprofessie zelf ten gevolge van AI. Dit is het zesde deel, met focus op mogelijke consequenties voor informatievraagstukken en rollen.
Deel 6 artikelenserie over kunstmatige intelligentie

Simon Been
Directeur van het Papieren Tijger Netwerk en spreker/trainer/auteur over AI in het informatiedomein




De lijst is veel langer. Heb je een tip voor een goede, handige chatbot? Mail naar redactie@informatieprofessional.nl en we voegen deze toe aan de lijst die we publiceren in de volgende editie van IP.
OVERZICHT(JE) VAN CHATBOTS
> ChatGPT
> Google Bard
> Google Gemini
> Meta AI
> HuggingChat (open source)
> Zapier AI Chatbot
> Microsoft Copilot (met Bing)
> Perplexity
> YouChat
> KoalaChat
> Jasper Chat
> MetaGPT
> Claude
> Ernie Bot
> Bloom
> Character.ai

Kunstmatige intelligentie en met name de golf van revolutionaire chatbots zoals OpenAI’s ChatGPT, Microsofts Copilot en Googles Gemini richten zich bij uitstek op informatievraagstukken. In een eerder artikel zijn bijvoorbeeld wat activiteiten geschetst waarbij een informatiemanager door AI kan worden ondersteund. Zo kun je een hele lijst met functies langslopen, van archivaris en informatiespecialist tot socialemediamanager, kennismanager en datagovernancespecialist, en op elk daarvan inzoomen.
BUSINESSCASES VOOR AI
Ook zijn er belangrijke businesscases, uitstijgend boven functies, te bedenken. Zoals met generatieve AI ‘de papierberg wegwerken’ of ‘het verleden toegankelijk maken’. Zie de geweldige case hierover van Stadsarchief Amsterdam in de vorige IP. Een andere fascinerende toepassing van AI is de chatbot waarmee je organisatie ‘praat’ met klanten of burgers. En de interne chatbot die vragen van collega’s beantwoordt over de dienstverlening van jouw afdeling of over het gebruik van bepaalde tools, of die gericht advies geeft over het omgaan met specifieke onderwerpen.
Zo zijn er diverse informatievraagstukken die potentieel tot interessante businesscases leiden: toepassingen met een grootschaliger impact die ook qua kosten de moeite waard zijn om in te investeren. Om dat inzichtelijk maken is het altijd handig om modellen te ontwikkelen, al hangt het nut af van het type organisatie en de omvang ervan.
VOORBEELD: INFORMATIEBEHEER
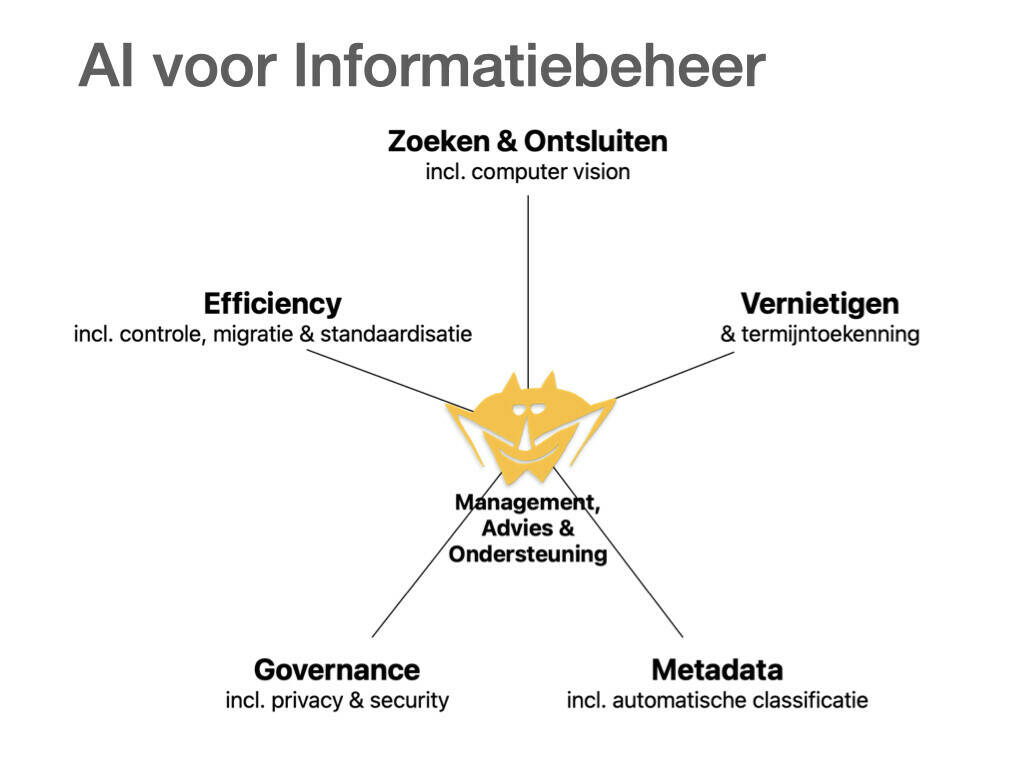
Laten we eens focussen op het domein informatiebeheer. Het model in afbeelding 1 noemt als eerste zoeken & ontsluiten, inclusief computer vision. De Stadsarchief Amsterdam-case, waarbij grote hoeveelheden historische manuscripten met AI en handwritten text recognition (HTR) toegankelijk en doorzoekbaar worden gemaakt, is een voorbeeld, maar de mogelijkheden gaan veel verder. Denk aan integratie van AI in de zoekfunctionaliteit van het (archief)systeem en aan semantisch zoeken, of aan het beter ontsluiten van al bestaande scans en pdf’s.
Ook voor vernietigen & bewaartermijntoekenning kan AI van toegevoegde waarde zijn. Net als bij zoeken & ontsluiten zullen er fouten worden gemaakt, al is de kans meestal klein. Daartegenover staat een forse tijdswinst. En: steekproefsgewijs kun je toetsen wat AI voor vernietiging opzij heeft gezet totdat je voldoende vertrouwen hebt om dit volledig automatisch te laten doen.
Hoelang kennen we al de belofte van automatische metadatering & classificatie? Rond de millenniumwisseling werd al geclaimd dat handmatige metadatering tot het verleden behoorde. Niet dus. En nu beweert AI dit varkentje wel even te zullen wassen ... De huidige hoeveelheid intelligentie mag dan indrukwekkend zijn, maar zoals zo vaak met AI moet het model wel met voldoende basismateriaal worden getraind. Met hulp van AI. Die is natuurlijk heel goed in het vaststellen van kruisverbanden, inclusief informatie over onder meer de opsteller, de applicatie, het onderwerp, het project of de zaak, en daarmee in het vereenvoudigen van zoekopdrachten.
VEELBELOVENDE POLITIEAGENT
Governance en met name privacy & security, het volgende punt in afbeelding 1, zijn ook een interessant gebied. Kunstmatige intelligentie is een veelbelovende politieagent als het gaat om gegevenslekken, toegangspogingen en compliance.
Verder ligt efficiency sterk voor de hand als focuspunt. AI is een kei in het automatiseren van activiteiten. Controle, migratie en standaardisatie zijn voorbeelden: van het omzetten van complexe bestandsformaten naar standaardformaten (denk aan e-Depots) tot het monitoren van afwijkingen in processen.
Bovengenoemde toepassingen richten zich vooral op het stroomlijnen van productieve activiteiten. Daarnaast kan AI toegevoegde waarde bieden op gebieden als management, advies & ondersteuning. Denk aan het inzicht geven in trends en patronen met het oogmerk om dienstverlening te verbeteren, mits er voldoende data worden verzameld, en aan het ondersteunen van trainingsactiviteiten voor (collega-)medewerkers met betrekking tot informatiebeheer. Advisering via een eigen chatbot is al eerder genoemd.
IMPACT AI: NIEUWE ROLLEN
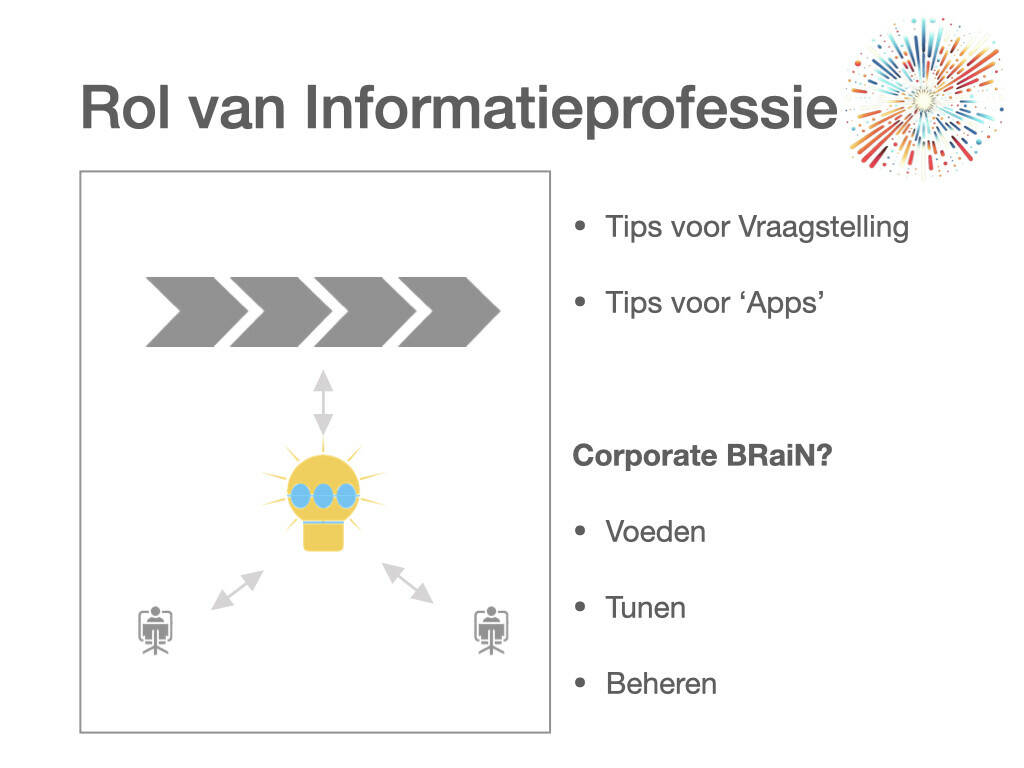
En zo kun je ook andere disciplines dan informatiebeheer onder de loep nemen. Laten we echter nog een stapje verder gaan: kan het zijn dat de rol van je afdeling, van de hele professie, gaat veranderen? Hoe kun je als informatiediscipline ondersteuning bieden als AI de organisatie binnenkomt? (zie afbeelding 2). Je hebt een rol richting de individuele gebruikers, systemen, afdelingen en primaire processen.
Je kunt natuurlijk gewoon helpen bij het gebruik: mensen leren hoe ze handige vragen kunnen stellen om makkelijker de juiste antwoorden te krijgen. Ook kun je bijvoorbeeld in ChatGPT specifieke apps maken met bedrijfsgerichte toepassingen.
De hamvraag is echter: wil je al die informatie ontsluiten via AI zodat gebruikers niet meer hoeven te zoeken om een antwoord te vinden maar iets kunnen vragen om een antwoord te krijgen? Interessanter nog: waarschijnlijk hoef je dat zelf niet eens te willen. Want voordat je het weet, vraagt je organisatie om een soort Corporate BRaiN: een eigen AI, gevoed met de eigen documenten, data en andere informatie – misschien alle vastgestelde documenten, misschien een subset. Als je ziet hoe de ontwikkelingen gaan, lijkt dat op termijn onvermijdelijk.
Zoals Harvard Business Review op 26 maart 2024 schrijft in het artikel ‘Is Your Company’s Data Ready for Generative AI?’: ‘For generative AI to be truly valuable to companies, they need to customize vendors’ language or image models with their own data, and do the internal work to prepare their data for that integration.’
SCHRIKBEELD
Uiteraard hebben we al ruime ervaring met dergelijke bewegingen en weten we hoe dat kan aflopen, zeker als ons ‘tafelzilver’ – digitale documenten – buiten onze grip terechtkomt. Het scenario is bekend. Plotseling komt een vliegwiel op gang: managers die bang worden de boot te missen, ICT’ers die een fascinerend nieuw terrein ontdekken en – niet te vergeten – leveranciers die een lucratief verdienmodel zien: extra licenties en een nog grotere lock-in.
Hier en daar opperen bepaalde mensen al om ‘365 in een grote bak te gooien en dat te bevragen’. Een schrikbeeld. Het allerminste wat je immers wilt, is weten of informatie als ‘juist’ is vastgesteld. Zo moet het dus niet, maar hoe dan wel?
KEUZES, KEUZES, KEUZES
Het mooiste is om te beginnen met onbetwiste informatie, maar even belangrijk is het om je doel vast te stellen: de inzet van AI heeft een goede basis nodig. Doe je het ‘omdat het nu kan’ of zijn er specifieke toepassingsgebieden? Dat heeft consequenties op verschillende terreinen, met name op inhoud, vorm, methode, beheer en voeding.
Wil je ‘alles’ erin stoppen of alleen informatie voor specifiek gebruik? Wanneer is inhoud geschikt? Welke bronnen zijn betrouwbaar? Hoe belangrijk is actualiteit? Gaat een document er in zijn geheel in of alleen ‘stukjes’ eruit? Je kunt documenten namelijk ‘voorbehandelen’, waardoor de onderliggende informatie wordt losgeweekt en alleen dat deel in de doorzoekbare database komt, en niet de documenten zelf. Zo hangen doel, vorm en methode samen.
Bij dit voeden en tunen kunnen zowel data-engineers als informatieprofessionals een belangrijke rol spelen: zij kunnen de vertaalslag maken tussen wat belangrijk is voor de organisatie en de data zelf. Iemand moet tenslotte weten welke informatie in welke vorm het meest geschikt is. Denk ook aan batchgewijs informatie ontsluiten: titel, korte beschrijving, kernwoorden, status (vastgesteld of niet en dergelijke); uiteraard ondersteund door AI.
Vergeet niet: straks gaat natuurlijk half Nederland met Microsoft aan de slag voor AI. Tegelijkertijd moet de overstap naar een andere partij – meestal in theorie – mogelijk blijven. Hoe doe je dat? Dit moet je van tevoren al regelen.
DE EVOLUTIE VAN BEHEER
Stel dat zo’n Corporate BRaiN er komt, wie gaat dit dan structureel beheren? Dan heb ik het niet alleen over de bronbestanden, maar ook over de gestelde vragen, de gegeven antwoorden en de kennisgroei. Die kennisgroei bestaat uit continue aanvulling, maar ook uit ‘organische’ groei doordat met het groeien van het brein binnenin eveneens nieuwe inzichten ontstaan. Bij de aanvullingen kunnen verschillende disciplines een rol spelen, afhankelijk van het type organisatie: communicatie, kennismanagement, bibliotheek, secretariaten en sowieso informatiebeheer, en natuurlijk ICT, business owners en proceseigenaren als het over data gaat. Het overall beheer zou logischerwijs thuishoren bij de discipline informatiebeheer, maar is zij daaraan toe?
Dit is een vraagstuk waarover we allemaal moeten nadenken. Want het begint met die ene vraag: ‘Jij bent toch de keeper, de schatbewaarder? Kom maar op met die informatie.’ Die vraag komt echt, en weet je dan wat je wilt? Welke rol je dan ambieert? En belangrijker nog: hoe ben je die vraag vóór? Zit je wel in de ‘besluitvormingsloop’? Kun je het proces voeden met doordachte aanbevelingen? De kop in het zand steken is geen optie, achteraan in de rij aansluiten heeft nog nooit goed uitgepakt. Beeldvorming op voorhand is essentieel.
ER IS HOOP. OF TOCH NIET?
In dit opzicht is het in mijn ogen onvergeeflijk hoe de overheid – bij uitstek de plek waar de informatiediscipline een spilfunctie bekleedt – opzettelijk alle betrokkenen dom houdt, terwijl de leveranciers de messen slijpen. Laten we hopen dat daar binnenkort een uitgekiend top-downbeleid komt waarin de informatieprofessie een sleutelrol krijgt bij de AI-aanpak. Fingers crossed.
Gelukkig klinken er ook andere stemmen in Den Haag. Bijvoorbeeld die van VU-professor en senior wetenschapper bij de Wetenschappelijke Raad voor het Regeringsbeleid (WRR) Haroon Sheikh. Hij adviseert bestuurders van organisaties: ‘AI goed inpassen in de organisatie, dat doe je niet door een totaalplan te maken, maar door er lokaal mee te experimenteren. De mensen op de vloer, zoals medewerkers van callcenters, weten het beste wat nodig is. Faciliteer dus dat zij ermee kunnen experimenteren. Liever duizend kleine experimenten dan één groot experiment. Zo kun je als organisatie ervaring opdoen en leren. Vallen en opstaan horen daarbij.’
Sheikh snapt het. Ook stelt het eerdergenoemde Harvard Business Review-artikel over de onderzochte chief data officers: ‘Almost a third said they were “experimenting at the individual level” [...] An additional 21% indicated that they were experimenting, but with usage guidelines for employees. [...] A surprising 16% noted that their organizations had banned use by employees, though that approach seems to be decreasing over time as companies handle data privacy issues with enterprise versions of generative AI models.’ Ook veelbelovend, maar … dat is in de Verenigde Staten.
‘VERBOD’ BIJ OVERHEID
Mijn eigen, huidige ervaring is echter ontnuchterend: zelfs de meest geïnteresseerde informatieprofessionals – de deelnemers aan bijeenkomsten en workshops over AI – hebben doorgaans minimale gebruikservaring met en inzicht in ChatGPT en dergelijke. En sinds de publicatie van het voorlopig overheidsstandpunt (zeg maar het ‘verbod’) lijken professionals werkzaam bij de rijksoverheid, gemeenten en provincies helemaal een stap terug te doen in het gebruik van AI, ondanks het feit dat beleidsambtenaren er tot eind 2023 volop mee experimenteerden en werkten om het nut ervan te doorgronden. Ook recentelijk hoorde ik van een forse overheidsorganisatie waar de ChatGPT-censuur is afgekondigd.
Hoe kom je tot een eigen visie en stellingname als je de materie niet begrijpt of er zelfs met een boog omheen loopt?
NIEUWE ROLLEN
Laten we het positieve scenario volgen: AI krijgt een geleidelijke, brede introductie binnen jouw organisatie, en de informatieprofessie vervult daarbij een sleutelrol door de genoemde activiteiten te ondernemen. Eigenlijk gaat dat verder dan ‘een wat uitgebreider takenpakket’; hier is sprake van nieuwe rollen. Ik noem (zie ook afbeelding 3):
> AI-Voeder: zorgt voor aanlevering van informatie, in welke vorm dan ook, en voor updates.
> AI-Tuner, ook wel AI-Fluisteraar: speelt een sleutelrol bij de eerdergenoemde tuning, vertaalslagen en voorbehandeling.
> BRaiN-Wachter: stort zich op het beheer, inclusief de bronbestanden, de vragen en antwoorden en de kennisgroei.
> Waarheids-Bewaker: heeft een inhoudelijke focus en signaleert, markeert, parkeert of verwijdert zelfs wat wordt gekenmerkt als ‘fake’, ‘betwist’, ‘AI-bewerkt’ of ‘bevat een redeneerfout’.
Wat de BRaiN-Wachter betreft: het loggen van vragen en antwoorden kan een dubbele functie hebben. Enerzijds omdat het simpelweg extra informatie oplevert, al is het maar vanuit statistisch oogpunt. Anderzijds, zeker in de overheidshoek, om helderheid te bieden over de besluitvormingsprocessen. Vergelijk het met sms-verkeer: welk vraag- en antwoordspel heeft er plaatsgevonden? En om mogelijke AI-invloed te kunnen vaststellen: heeft de interactie met een AI invloed gehad op bepaalde beslissingen of documenten, zo ja, in welke mate?, en is er reden om aan te nemen dat dit heeft geleid tot verkeerde beslissingen?
Daarmee komen we ook bij de rol van de Waarheids-Bewaker en bij het signaleren, markeren, parkeren of zelfs verwijderen van onware informatie. Of vind je dat geen onderdeel van je missie? Wat ís eigenlijk je missie? Niet bezien vanuit organisatorische doelen en taakomschrijvingen, maar vanuit de helikopter, vanuit het werkelijke organisatiebelang?
NIEUWE AMBITIES
De informatiefunctie ondersteunt de (primaire) processen en de interne en soms externe betrokkenen met kennis en informatie, maar de grote buitenwereld heeft ook belangen – van geschiedschrijving tot inzicht in het organisatorisch functioneren. De informatieprofessie heeft dan ook naast de pure interne taak een maatschappelijke: het afleggen van verantwoording mogelijk maken, zij het voor de fiscus of accountants, of voor openheid binnen de overheid. En eigenlijk gaat het nog een stukje verder: ons collectieve maatschappelijke geheugen.
In die maatschappij wordt de waarheid een steeds belangrijker thema, en in het AI-tijdperk groeit dat belang alleen maar: wat is eigenlijk ‘waar’? Elke onwaarheid die over jouw organisatie wordt geuit besmet de perceptie ervan. Behoort het (binnenkort) tot jouw missie om in de buitenwereld te zorgen voor kloppende kennis over je organisatie en haar domein door pertinente onjuistheden te weerleggen of in elk geval te documenteren? Geen geringe opgave. Communicatieafdelingen doen dat soms al.
Het gaat nog een stapje verder: elke onwaarheid die over jouw organisatie wordt geuit besmet niet alleen de huidige maar ook de toekomstige perceptie ervan omdat deze wordt toegevoegd aan het collectieve bewustzijn van de planeet: het internet en dus ook de verschillende AI’s. Neemt je organisatie een maatschappelijke verantwoordelijkheid (en een verantwoordelijkheid voor het eigenbelang) gericht op bewaking van die juiste informatie voor de toekomst?
Pittige vragen, maar ze zijn nodig.
ONTDEK JE ROL EN PAK HEM!
Mijn insteek rond AI is zorgen voor geleide bewustwording en het vermijden van zeer voorspelbare valkuilen. Ik adviseer om ChatGPT & Co vooral te gebruiken als sparringpartner en als tool voor specifieke taken en vraagstukken, maar ook om na te denken over nieuwe rollen en misschien zelfs ambities voor de toekomst. Mijmer erover, discussieer erover, en laat je niet tegenhouden door bange bestuurders.
Ik noemde AI ooit een teamsport. Doe het vooral met je team, ga samen op die ontdekkingsreis. Laat je uitdagen en inspireren. Lees erover. Luister. Kijk. Leer. <
‘Steekproefsgewijs kun je toetsen wat AI voor vernietiging opzij heeft gezet totdat je voldoende vertrouwen hebt om dit automatisch te laten doen’
‘Wil je al die informatie ontsluiten via AI, zodat gebruikers niet meer hoeven te zoeken om een antwoord te vinden maar iets kunnen vragen om een antwoord te krijgen?’
‘Hier en daar opperen bepaalde mensen al om “365 in een grote bak te gooien en dat te bevragen” – een schrikbeeld’
‘Het is onvergeeflijk hoe juist de overheid – bij uitstek de plek waar de informatiediscipline een spilfunctie bekleedt – opzettelijk alle betrokkenen dom houdt’
‘De meest geïnteresseerde informatieprofessionals hebben doorgaans minimale gebruikservaring met en inzicht in ChatGPT en dergelijke’
‘Hoe kom je tot een eigen visie en stellingname als je de materie niet begrijpt of er zelfs met een boog omheen loopt?’
DE VOORGAANDE DELEN
VAN DEZE SERIE LEZEN?
Je vindt ze in het online archief op
de IP-website. Klik hieronder voor:
> DEEL 1
> DEEL 2
> DEEL 3
> DEEL 4
> DEEL 5

IP | vakblad voor informatieprofessionals | 03 / 2024

Simon Been
Directeur van het Papieren Tijger Netwerk en spreker/trainer/auteur over AI in het informatiedomein
AI IN HET INFORMATIEDOMEIN (6) SIMON BEEN
Deel 6 artikelenserie over kunstmatige intelligentie
Wat is de impact van kunstmatige intelligentie op het informatiedomein? In een reeks artikelen wordt ingegaan op persoonlijke activiteiten binnen het informatiedomein en veranderingen in organisatieprocessen en de informatieprofessie zelf ten gevolge van AI. Dit is het zesde deel, met focus op mogelijke consequenties voor informatievraagstukken en rollen.


De lijst is veel langer. Heb je een tip voor een goede, handige chatbot? Mail naar redactie@informatieprofessional.nl en we voegen deze toe aan de lijst die we publiceren in de volgende editie van IP.
OVERZICHT(JE) VAN CHATBOTS
> ChatGPT
> Google Bard
> Google Gemini
> Meta AI
> HuggingChat (open source)
> Zapier AI Chatbot
> Microsoft Copilot (met Bing)
> Perplexity
> YouChat
> KoalaChat
> Jasper Chat
> MetaGPT
> Claude
> Ernie Bot
> Bloom
> Character.ai
NIEUWE ROLLEN
Laten we het positieve scenario volgen: AI krijgt een geleidelijke, brede introductie binnen jouw organisatie, en de informatieprofessie vervult daarbij een sleutelrol door de genoemde activiteiten te ondernemen. Eigenlijk gaat dat verder dan ‘een wat uitgebreider takenpakket’; hier is sprake van nieuwe rollen. Ik noem (zie ook afbeelding 3):
> AI-Voeder: zorgt voor aanlevering van informatie, in welke vorm dan ook, en voor updates.
> AI-Tuner, ook wel AI-Fluisteraar: speelt een sleutelrol bij de eerdergenoemde tuning, vertaalslagen en voorbehandeling.
> BRaiN-Wachter: stort zich op het beheer, inclusief de bronbestanden, de vragen en antwoorden en de kennisgroei.
> Waarheids-Bewaker: heeft een inhoudelijke focus en signaleert, markeert, parkeert of verwijdert zelfs wat wordt gekenmerkt als ‘fake’, ‘betwist’, ‘AI-bewerkt’ of ‘bevat een redeneerfout’.
Wat de BRaiN-Wachter betreft: het loggen van vragen en antwoorden kan een dubbele functie hebben. Enerzijds omdat het simpelweg extra informatie oplevert, al is het maar vanuit statistisch oogpunt. Anderzijds, zeker in de overheidshoek, om helderheid te bieden over de besluitvormingsprocessen. Vergelijk het met sms-verkeer: welk vraag- en antwoordspel heeft er plaatsgevonden? En om mogelijke AI-invloed te kunnen vaststellen: heeft de interactie met een AI invloed gehad op bepaalde beslissingen of documenten, zo ja, in welke mate?, en is er reden om aan te nemen dat dit heeft geleid tot verkeerde beslissingen?
Daarmee komen we ook bij de rol van de Waarheids-Bewaker en bij het signaleren, markeren, parkeren of zelfs verwijderen van onware informatie. Of vind je dat geen onderdeel van je missie? Wat ís eigenlijk je missie? Niet bezien vanuit organisatorische doelen en taakomschrijvingen, maar vanuit de helikopter, vanuit het werkelijke organisatiebelang?
NIEUWE AMBITIES
De informatiefunctie ondersteunt de (primaire) processen en de interne en soms externe betrokkenen met kennis en informatie, maar de grote buitenwereld heeft ook belangen – van geschiedschrijving tot inzicht in het organisatorisch functioneren. De informatieprofessie heeft dan ook naast de pure interne taak een maatschappelijke: het afleggen van verantwoording mogelijk maken, zij het voor de fiscus of accountants, of voor openheid binnen de overheid. En eigenlijk gaat het nog een stukje verder: ons collectieve maatschappelijke geheugen.
In die maatschappij wordt de waarheid een steeds belangrijker thema, en in het AI-tijdperk groeit dat belang alleen maar: wat is eigenlijk ‘waar’? Elke onwaarheid die over jouw organisatie wordt geuit besmet de perceptie ervan. Behoort het (binnenkort) tot jouw missie om in de buitenwereld te zorgen voor kloppende kennis over je organisatie en haar domein door pertinente onjuistheden te weerleggen of in elk geval te documenteren? Geen geringe opgave. Communicatieafdelingen doen dat soms al.
Het gaat nog een stapje verder: elke onwaarheid die over jouw organisatie wordt geuit besmet niet alleen de huidige maar ook de toekomstige perceptie ervan omdat deze wordt toegevoegd aan het collectieve bewustzijn van de planeet: het internet en dus ook de verschillende AI’s. Neemt je organisatie een maatschappelijke verantwoordelijkheid (en een verantwoordelijkheid voor het eigenbelang) gericht op bewaking van die juiste informatie voor de toekomst?
Pittige vragen, maar ze zijn nodig.
ONTDEK JE ROL EN PAK HEM!
Mijn insteek rond AI is zorgen voor geleide bewustwording en het vermijden van zeer voorspelbare valkuilen. Ik adviseer om ChatGPT & Co vooral te gebruiken als sparringpartner en als tool voor specifieke taken en vraagstukken, maar ook om na te denken over nieuwe rollen en misschien zelfs ambities voor de toekomst. Mijmer erover, discussieer erover, en laat je niet tegenhouden door bange bestuurders.
Ik noemde AI ooit een teamsport. Doe het vooral met je team, ga samen op die ontdekkingsreis. Laat je uitdagen en inspireren. Lees erover. Luister. Kijk. Leer. <
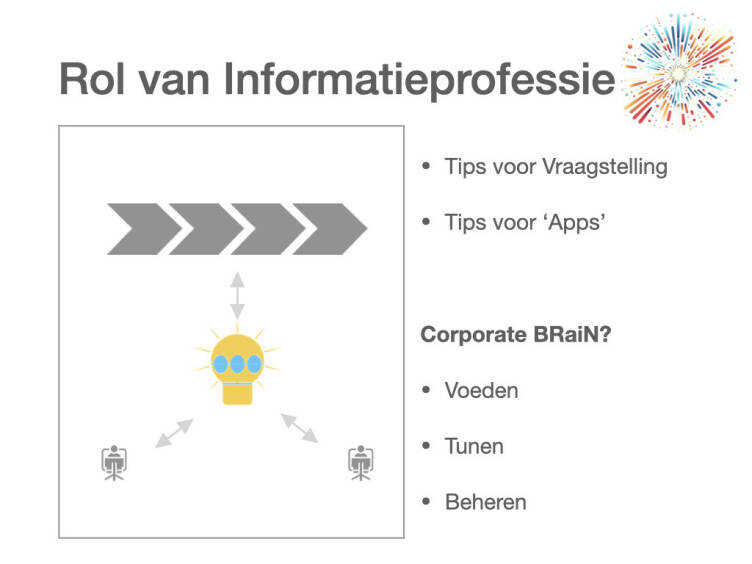
IMPACT AI: NIEUWE ROLLEN
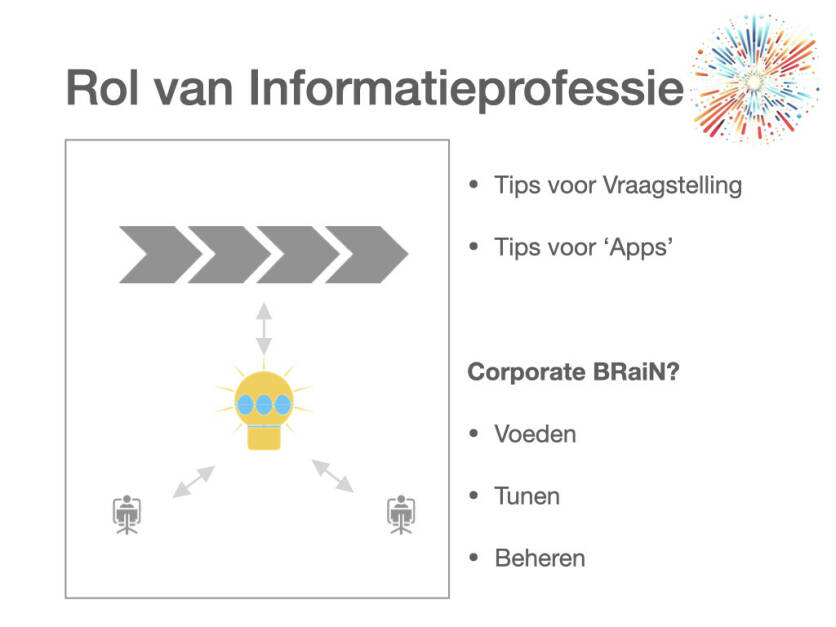
En zo kun je ook andere disciplines dan informatiebeheer onder de loep nemen. Laten we echter nog een stapje verder gaan: kan het zijn dat de rol van je afdeling, van de hele professie, gaat veranderen? Hoe kun je als informatiediscipline ondersteuning bieden als AI de organisatie binnenkomt? (zie afbeelding 2). Je hebt een rol richting de individuele gebruikers, systemen, afdelingen en primaire processen.
Je kunt natuurlijk gewoon helpen bij het gebruik: mensen leren hoe ze handige vragen kunnen stellen om makkelijker de juiste antwoorden te krijgen. Ook kun je bijvoorbeeld in ChatGPT specifieke apps maken met bedrijfsgerichte toepassingen.
De hamvraag is echter: wil je al die informatie ontsluiten via AI zodat gebruikers niet meer hoeven te zoeken om een antwoord te vinden maar iets kunnen vragen om een antwoord te krijgen? Interessanter nog: waarschijnlijk hoef je dat zelf niet eens te willen. Want voordat je het weet, vraagt je organisatie om een soort Corporate BRaiN: een eigen AI, gevoed met de eigen documenten, data en andere informatie – misschien alle vastgestelde documenten, misschien een subset. Als je ziet hoe de ontwikkelingen gaan, lijkt dat op termijn onvermijdelijk.
Zoals Harvard Business Review op 26 maart 2024 schrijft in het artikel ‘Is Your Company’s Data Ready for Generative AI?’: ‘For generative AI to be truly valuable to companies, they need to customize vendors’ language or image models with their own data, and do the internal work to prepare their data for that integration.’
SCHRIKBEELD
Uiteraard hebben we al ruime ervaring met dergelijke bewegingen en weten we hoe dat kan aflopen, zeker als ons ‘tafelzilver’ – digitale documenten – buiten onze grip terechtkomt. Het scenario is bekend. Plotseling komt een vliegwiel op gang: managers die bang worden de boot te missen, ICT’ers die een fascinerend nieuw terrein ontdekken en – niet te vergeten – leveranciers die een lucratief verdienmodel zien: extra licenties en een nog grotere lock-in.
Hier en daar opperen bepaalde mensen al om ‘365 in een grote bak te gooien en dat te bevragen’. Een schrikbeeld. Het allerminste wat je immers wilt, is weten of informatie als ‘juist’ is vastgesteld. Zo moet het dus niet, maar hoe dan wel?
KEUZES, KEUZES, KEUZES
Het mooiste is om te beginnen met onbetwiste informatie, maar even belangrijk is het om je doel vast te stellen: de inzet van AI heeft een goede basis nodig. Doe je het ‘omdat het nu kan’ of zijn er specifieke toepassingsgebieden? Dat heeft consequenties op verschillende terreinen, met name op inhoud, vorm, methode, beheer en voeding.
Wil je ‘alles’ erin stoppen of alleen informatie voor specifiek gebruik? Wanneer is inhoud geschikt? Welke bronnen zijn betrouwbaar? Hoe belangrijk is actualiteit? Gaat een document er in zijn geheel in of alleen ‘stukjes’ eruit? Je kunt documenten namelijk ‘voorbehandelen’, waardoor de onderliggende informatie wordt losgeweekt en alleen dat deel in de doorzoekbare database komt, en niet de documenten zelf. Zo hangen doel, vorm en methode samen.
Bij dit voeden en tunen kunnen zowel data-engineers als informatieprofessionals een belangrijke rol spelen: zij kunnen de vertaalslag maken tussen wat belangrijk is voor de organisatie en de data zelf. Iemand moet tenslotte weten welke informatie in welke vorm het meest geschikt is. Denk ook aan batchgewijs informatie ontsluiten: titel, korte beschrijving, kernwoorden, status (vastgesteld of niet en dergelijke); uiteraard ondersteund door AI.
Vergeet niet: straks gaat natuurlijk half Nederland met Microsoft aan de slag voor AI. Tegelijkertijd moet de overstap naar een andere partij – meestal in theorie – mogelijk blijven. Hoe doe je dat? Dit moet je van tevoren al regelen.
DE EVOLUTIE VAN BEHEER
Stel dat zo’n Corporate BRaiN er komt, wie gaat dit dan structureel beheren? Dan heb ik het niet alleen over de bronbestanden, maar ook over de gestelde vragen, de gegeven antwoorden en de kennisgroei. Die kennisgroei bestaat uit continue aanvulling, maar ook uit ‘organische’ groei doordat met het groeien van het brein binnenin eveneens nieuwe inzichten ontstaan. Bij de aanvullingen kunnen verschillende disciplines een rol spelen, afhankelijk van het type organisatie: communicatie, kennismanagement, bibliotheek, secretariaten en sowieso informatiebeheer, en natuurlijk ICT, business owners en proceseigenaren als het over data gaat. Het overall beheer zou logischerwijs thuishoren bij de discipline informatiebeheer, maar is zij daaraan toe?
Dit is een vraagstuk waarover we allemaal moeten nadenken. Want het begint met die ene vraag: ‘Jij bent toch de keeper, de schatbewaarder? Kom maar op met die informatie.’ Die vraag komt echt, en weet je dan wat je wilt? Welke rol je dan ambieert? En belangrijker nog: hoe ben je die vraag vóór? Zit je wel in de ‘besluitvormingsloop’? Kun je het proces voeden met doordachte aanbevelingen? De kop in het zand steken is geen optie, achteraan in de rij aansluiten heeft nog nooit goed uitgepakt. Beeldvorming op voorhand is essentieel.
ER IS HOOP. OF TOCH NIET?
In dit opzicht is het in mijn ogen onvergeeflijk hoe de overheid – bij uitstek de plek waar de informatiediscipline een spilfunctie bekleedt – opzettelijk alle betrokkenen dom houdt, terwijl de leveranciers de messen slijpen. Laten we hopen dat daar binnenkort een uitgekiend top-downbeleid komt waarin de informatieprofessie een sleutelrol krijgt bij de AI-aanpak. Fingers crossed.
Gelukkig klinken er ook andere stemmen in Den Haag. Bijvoorbeeld die van VU-professor en senior wetenschapper bij de Wetenschappelijke Raad voor het Regeringsbeleid (WRR) Haroon Sheikh. Hij adviseert bestuurders van organisaties: ‘AI goed inpassen in de organisatie, dat doe je niet door een totaalplan te maken, maar door er lokaal mee te experimenteren. De mensen op de vloer, zoals medewerkers van callcenters, weten het beste wat nodig is. Faciliteer dus dat zij ermee kunnen experimenteren. Liever duizend kleine experimenten dan één groot experiment. Zo kun je als organisatie ervaring opdoen en leren. Vallen en opstaan horen daarbij.’
Sheikh snapt het. Ook stelt het eerdergenoemde Harvard Business Review-artikel over de onderzochte chief data officers: ‘Almost a third said they were “experimenting at the individual level” [...] An additional 21% indicated that they were experimenting, but with usage guidelines for employees. [...] A surprising 16% noted that their organizations had banned use by employees, though that approach seems to be decreasing over time as companies handle data privacy issues with enterprise versions of generative AI models.’ Ook veelbelovend, maar … dat is in de Verenigde Staten.
‘VERBOD’ BIJ OVERHEID
Mijn eigen, huidige ervaring is echter ontnuchterend: zelfs de meest geïnteresseerde informatieprofessionals – de deelnemers aan bijeenkomsten en workshops over AI – hebben doorgaans minimale gebruikservaring met en inzicht in ChatGPT en dergelijke. En sinds de publicatie van het voorlopig overheidsstandpunt (zeg maar het ‘verbod’) lijken professionals werkzaam bij de rijksoverheid, gemeenten en provincies helemaal een stap terug te doen in het gebruik van AI, ondanks het feit dat beleidsambtenaren er tot eind 2023 volop mee experimenteerden en werkten om het nut ervan te doorgronden. Ook recentelijk hoorde ik van een forse overheidsorganisatie waar de ChatGPT-censuur is afgekondigd.
Hoe kom je tot een eigen visie en stellingname als je de materie niet begrijpt of er zelfs met een boog omheen loopt?
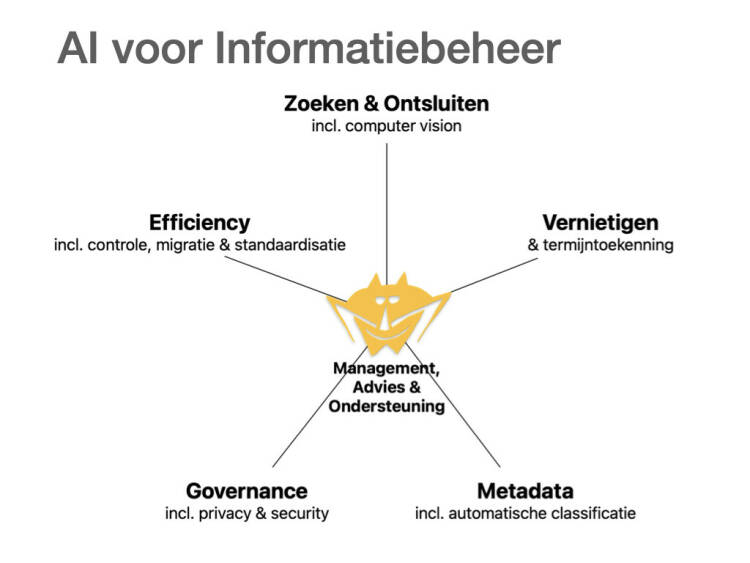
VOORBEELD: INFORMATIEBEHEER
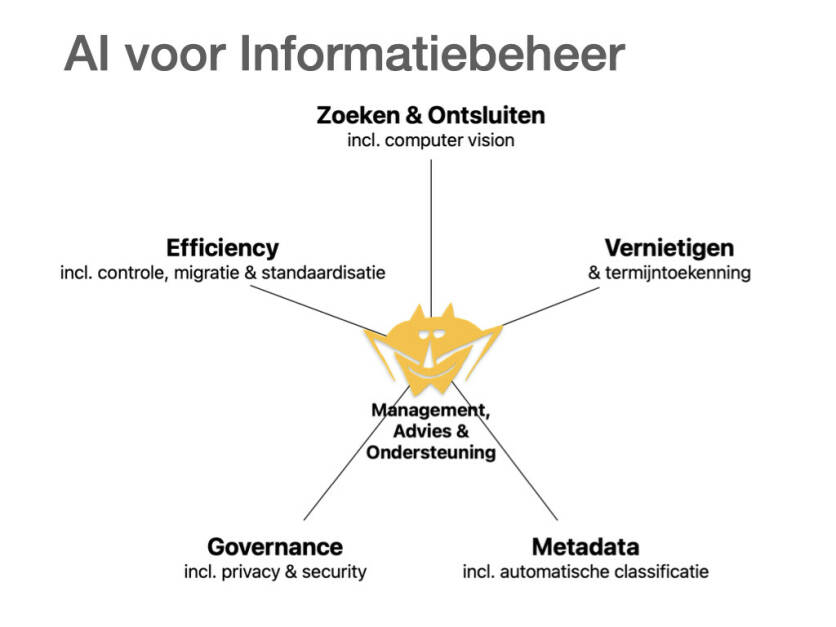
Laten we eens focussen op het domein informatiebeheer. Het model in afbeelding 1 noemt als eerste zoeken & ontsluiten, inclusief computer vision. De Stadsarchief Amsterdam-case, waarbij grote hoeveelheden historische manuscripten met AI en handwritten text recognition (HTR) toegankelijk en doorzoekbaar worden gemaakt, is een voorbeeld, maar de mogelijkheden gaan veel verder. Denk aan integratie van AI in de zoekfunctionaliteit van het (archief)systeem en aan semantisch zoeken, of aan het beter ontsluiten van al bestaande scans en pdf’s.
Ook voor vernietigen & bewaartermijntoekenning kan AI van toegevoegde waarde zijn. Net als bij zoeken & ontsluiten zullen er fouten worden gemaakt, al is de kans meestal klein. Daartegenover staat een forse tijdswinst. En: steekproefsgewijs kun je toetsen wat AI voor vernietiging opzij heeft gezet totdat je voldoende vertrouwen hebt om dit volledig automatisch te laten doen.
Hoelang kennen we al de belofte van automatische metadatering & classificatie? Rond de millenniumwisseling werd al geclaimd dat handmatige metadatering tot het verleden behoorde. Niet dus. En nu beweert AI dit varkentje wel even te zullen wassen ... De huidige hoeveelheid intelligentie mag dan indrukwekkend zijn, maar zoals zo vaak met AI moet het model wel met voldoende basismateriaal worden getraind. Met hulp van AI. Die is natuurlijk heel goed in het vaststellen van kruisverbanden, inclusief informatie over onder meer de opsteller, de applicatie, het onderwerp, het project of de zaak, en daarmee in het vereenvoudigen van zoekopdrachten.
VEELBELOVENDE POLITIEAGENT
Governance en met name privacy & security, het volgende punt in afbeelding 1, zijn ook een interessant gebied. Kunstmatige intelligentie is een veelbelovende politieagent als het gaat om gegevenslekken, toegangspogingen en compliance.
Verder ligt efficiency sterk voor de hand als focuspunt. AI is een kei in het automatiseren van activiteiten. Controle, migratie en standaardisatie zijn voorbeelden: van het omzetten van complexe bestandsformaten naar standaardformaten (denk aan e-Depots) tot het monitoren van afwijkingen in processen.
Bovengenoemde toepassingen richten zich vooral op het stroomlijnen van productieve activiteiten. Daarnaast kan AI toegevoegde waarde bieden op gebieden als management, advies & ondersteuning. Denk aan het inzicht geven in trends en patronen met het oogmerk om dienstverlening te verbeteren, mits er voldoende data worden verzameld, en aan het ondersteunen van trainingsactiviteiten voor (collega-)medewerkers met betrekking tot informatiebeheer. Advisering via een eigen chatbot is al eerder genoemd.
Kunstmatige intelligentie en met name de golf van revolutionaire chatbots zoals OpenAI’s ChatGPT, Microsofts Copilot en Googles Gemini richten zich bij uitstek op informatievraagstukken. In een eerder artikel zijn bijvoorbeeld wat activiteiten geschetst waarbij een informatiemanager door AI kan worden ondersteund. Zo kun je een hele lijst met functies langslopen, van archivaris en informatiespecialist tot socialemediamanager, kennismanager en datagovernancespecialist, en op elk daarvan inzoomen.
BUSINESSCASES VOOR AI
Ook zijn er belangrijke businesscases, uitstijgend boven functies, te bedenken. Zoals met generatieve AI ‘de papierberg wegwerken’ of ‘het verleden toegankelijk maken’. Zie de geweldige case hierover van Stadsarchief Amsterdam in de vorige IP. Een andere fascinerende toepassing van AI is de chatbot waarmee je organisatie ‘praat’ met klanten of burgers. En de interne chatbot die vragen van collega’s beantwoordt over de dienstverlening van jouw afdeling of over het gebruik van bepaalde tools, of die gericht advies geeft over het omgaan met specifieke onderwerpen.
Zo zijn er diverse informatievraagstukken die potentieel tot interessante businesscases leiden: toepassingen met een grootschaliger impact die ook qua kosten de moeite waard zijn om in te investeren. Om dat inzichtelijk maken is het altijd handig om modellen te ontwikkelen, al hangt het nut af van het type organisatie en de omvang ervan.
DE VOORGAANDE DELEN
VAN DEZE SERIE LEZEN?
Je vindt ze in het online archief op
de IP-website. Klik hieronder voor:
> DEEL 1
> DEEL 2
> DEEL 3
> DEEL 4
> DEEL 5
IP | vakblad voor informatieprofessionals | 03 / 2024